Viral trends
Contents
13. Viral trends#
As we said last week, our objective is to delay and flatten the peak of the epidemic by bringing forward the right measures at the right time, so that we minimise suffering and save lives. And everything we do is based scrupulously on the best scientific advice.
In this case study we will experiment with fitting some data to the logistic and the Fréchet distributions. Each of these has a characteristic “sigmoidal” S-shape, which makes them typically suitable for fitting viral data. What we see with viruses is:
an initial “flat” period of little growth (the lag phase)
a period of exponential growth
a terminating plateau where transmission has almost reached the maximum possible
We will explore these features and the models that describe them later in this course. For now, we simply state the equations for the two distributions, which are given below. The effect of the parameters in each model is similar, with \(x_0\) and \(K\) determining the location and scale of the distribution, and \(s\) determining the shape.
A plot of the Fréchet distribution is shown below for particular choices of the parameters, by way of example. You may wish to experiment with plotting both the Fréchet and logistic function for a few different parameter values to see how they compare.
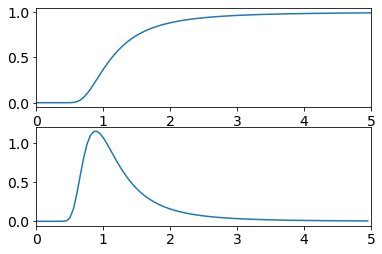
Fig. 13.1 Plots of the Fréchet distribution (top) and its growth rate (bottom) for \(x_0=0\), \(K=1\), \(s=3\)#
The exercises below will give you some practice at fitting data to either of these functions. It is easiest to do this if the data has been normalised to the range \([0,1]\), though only the Fréchet distribution requires this normalisation.
13.1. Coronavirus data#
The coronavirus (COVID-19) in the UK dashboard is an up-to-date weekly government summary of key coronavirus metrics, such as levels of infection and hospitalisations. You can download the data from coronavirus.data.gov.uk
The below plots are based on dashboard data to 22 Aug 2022, which can be found in data_2-22-Aug-17.csv.
13.1.1. Daily cases#
First we simply plot the daily reported cases. The background shading in the plots below indicates periods of lockdown (red) and significant restriction (yellow). Mostly this is just importing and plotting data, though some work needs to be done to deal with the x-axis values, which are given as dates.
The code also shows how the data can be de-noised by averaging over a 14-day moving window. The pandas library provides a moving window filter for this purpose.
#import the data
df = pd.read_csv('data_2022-Aug-17.csv')
df=df.iloc[::-1] #data in reverse order
#get the columns that we are interested in np format
import numpy as np
x=np.array(df['date'])
y=np.array(df['newCasesBySpecimenDate'])
#x is in datestring format. Convert it to a day counter:
from datetime import date as dt
date=dt.fromisoformat
dt0 = date(x[0])
x=[abs(date(x[i])-dt0).days for i in range(len(x))]
#set up the plot axis
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1,1,figsize=(8,2))
plt.xlim([0,x[-1]])
plt.ylim([0,1.2*max(y)])
#plot it
plt.plot(x,y)
#Average in each two week (14 day) interval
window_size = 14
df = pd.DataFrame({'days': x,'cases': y})
avg = df.rolling(window_size).mean()
smoothx=avg['days']
smoothy=avg['cases']
plt.plot(smoothx,smoothy,'k')
# <<<<<<<<<< Code to prettify can be inserted here
plt.show()
The code that was used here to prettify the plot are shown below if you are interested to see how it was done. You do not need to be able to do it!
# Key dates in pandemic timeline
d=[]
d.append("2020-03-23") # Start lockdown
d.append("2020-05-13") # Restricted
d.append("2020-07-04") # End lockdown
d.append("2020-11-05") # Start lockdown
d.append("2020-12-02") # Tiers
d.append("2021-01-05") # Start lockdown
d.append("2021-03-08") # End lockdown
keydates = [abs(date(i)-dt0).days for i in d]
# Background shading
plt.axvspan(keydates[0], keydates[1], facecolor='#ff2400', alpha=0.5) #1st lockdown
plt.axvspan(keydates[1], keydates[2], facecolor='#ffff00', alpha=0.5) #restricted
plt.axvspan(keydates[3], keydates[4], facecolor='#ff2400', alpha=0.5) #2nd lockdown
plt.axvspan(keydates[4], keydates[5], facecolor='#ffff00', alpha=0.5) #tiers
plt.axvspan(keydates[5], keydates[6], facecolor='#ff2400', alpha=0.5) #3rd lockdown
# Format tick marks and tick labels on x axis.
# Place a tick mark for first day of each month
xticks=[]
xtickl=[]
for i in range(1,32):
yr=2020+i//12
mo=np.mod(i,12)+1
datestr=dt(yr,mo,1)
xticks.append(abs(datestr-dt0).days)
xtickl.append(datestr.strftime("%b-%y"))
plt.xticks(xticks,labels=xtickl)
plt.xticks(rotation = 90)
plt.grid(axis = 'x')
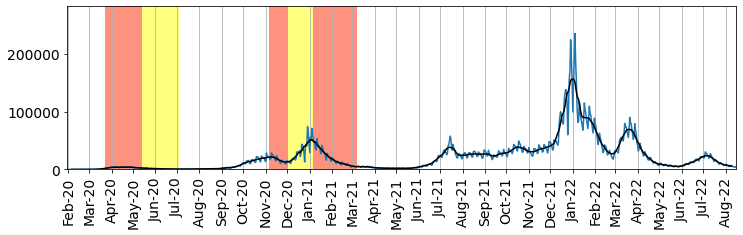
Fig. 13.2 Daily covid cases obtained from coronavirus (COVID-19) in the UK dashboard#
13.1.2. Growth rates and R values#
The smoothed data can be used to estimate daily growth rates in reporting over the period, which are shown below as percentages. Despite being calculated by crude methodology, the figures roughly match official statistics.
#Growth rate estimates in moving window
gr=100*np.diff(smoothy)/smoothy[0:-1]
fig, ax = plt.subplots(1,1,figsize=(8,2))
plt.plot(smoothx[0:-1],gr,'o',markersize=2)
plt.axhline(linewidth=2, color='k') # add horizontal axis
#note: some code to prettify the plot and add a trendline is excluded
plt.show()
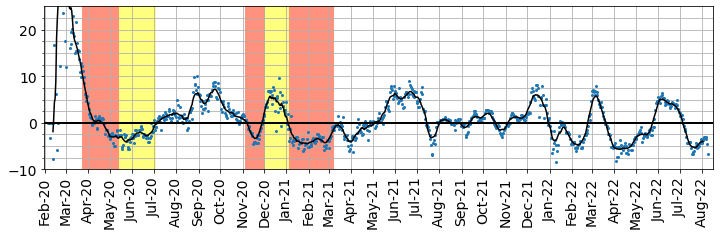
Fig. 13.3 Daily (averaged) covid growth rates (%) estimated from data reports.#
Estimating the R-number is a much more complicated business. Government values are based on aggregating calculations produced by mathematical models from several UK institutions. However, we can obtain a very rough-and-ready estimate of what the R value was a week ago by using the formula \(R_{est} = (1+6G)\), where \(G\) is the current growth rate as a decimal. Compare this plot with Fig 18 from a Royal Society paper:
fig, ax = plt.subplots(1,1,figsize=(8,2))
plt.plot(smoothx[0:-1]-n, 1+(n-1)*gr/100,'o',markersize=2)
plt.xlim([30,125])
plt.ylim([0,2.6])
plt.show()
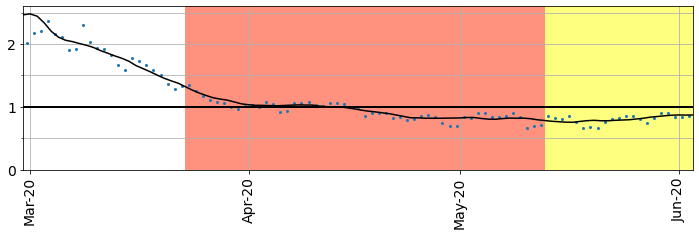
Fig. 13.4 Estimated R-value \(R_{est} = (1+6G)\), where \(G\) is the growth rate as a decimal, offset by one week.#
13.1.3. Fitting to a model#
Now let’s try to fit the data for the number of cases to a mathematical model. We will do this separately for each wave of the infection. The shading in the below plot is to identify the infection waves that we will look at.
The unfitted period between the identified third and fourth waves is peculiar. The sharp drop in cases coincides with the announcement of 19 July when legal limits on social contact were removed in England, including re-opening of nightclubs. For a timeline of restrictions, see this website.
{kind=link}
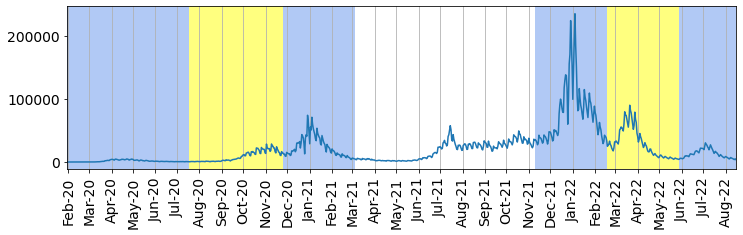
Fig. 13.5 Identifiable “waves” of infection are alternately highlighted in blue or yellow#
Exercise 13.1
Choose one of the “waves” by eye and isolate the \((x,y)\) data for this interval. For the data that you identified :
Normalise the \(x\) co-ordinate so that it runs from 0 to 1. You can do this by defining:
\(\qquad\quad\)xhat=(x-x[0])/(x[-1]-x[0]).Transform the \(y\) data to give a running total of infections, normalised to the range \([0,1]\). You can do this by defining
\(\quad\qquad\)yhat= np.cumsum(y-min(y))/np.sum(y-min(y)).Fit the following “logistic” function to the (
xhat,yhat) data and plot the fitted curve together with the data on the same axis:
Find the inverse transform corresponding to
yhat, and apply it to your fitted curve to create a new figure. Show your result together with the original (untransformed) \(y\) data on the same axis.
*Hint: The inverse of the np.cumsum function is the np.diff function.
13.2. Internet “memes”#
In 2012 the singer Carly Rae Jepsen released the song “Call Me Maybe”. The song was a huge worldwide hit and in Britain it become the second best-selling single of 2012. It’s popularity as an internet search term was further helped by viral videos which included a dance routine by the Miami dolphins cheerleaders and a parody by the US army.
We can obtain a log of interest over time in the search term “call me maybe” by interrogating Google Trends. The database allows you to search by timeframe and world location, and you can also distinguish between Google searches or YouTube searches.
The plot below shows the nomalised worldwide Google search data for the phrase call me maybe between 2/Jan/2011 and 28/Dec/2014. The data shows a surge in interest followed by a long, slow decline. This is similar to the data we saw for coronavirus cases, but with a longer tail.
Comparison of the plot with Fig. 13.1 suggest that the search data may possibly be a good candidate to fit to the Fréchet function.
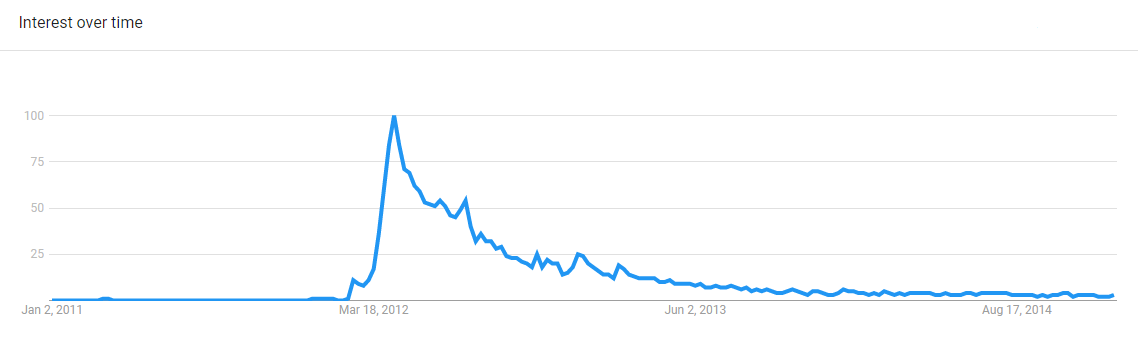
Fig. 13.6 Global interest over time in the search term call me maybe.#
Exercise 13.2
Fit a Fréchet function to the cumulative search interest for the call me maybe dataset. Present any plots that you think are useful to demonstrate the quality of the fit.
Exercise 13.3
Use Google trends to obtain search data for your own choice of meme/viral video and fit either the logistic function or the Fréchet function to the cumulative data.
You can choose between Worldwide or specific country. You can also choose Google search data or YouTube data. Provide the url link to the dataset you used. Did you obtain a good fit? Why do you think this is?